Punch Platform
![]()
Introduction
The Punch is a ready-to-go-production Kubernetes native FaaS/Serverless framework.
It is built on top of a foundation of key open source technologies such as OpenSearch/OpenDashboard, ClickHouse, Flink, Spark and Kafka, all packaged together with a number of business modules in a single well-documented and supported distribution.
The Punch is unique in a way that it gives users the ability to design data processing pipelines (called punchlines) using simple configuration files, compatible with various runtime engines to accommodate data science, data processing (ETLs) and log management use cases. It is a native Kubernetes solution and uses Kubernetes Custom Resource Definition files to express punchline configurations.
Punchlines cover a wide range of functional use cases :
- data collection and transport from edge to central platforms;
- data parsing;
- filtering and enrichment;
- real-time alerting;
- machine learning.
Combined with cutting edge data visualization capabilities, multi-tenancy and security, the Punch lets you go on production quickly, on cloud or on-premise infrastructures.
This asset is developed by Thales TCE/TSN Entity.
This documentation is a description of the Punchplatform capabilities in the K8saas context. It is directly followed with a concrete test case with a real-time parsing of logs from Azure to Opensearch.
How does a punchline works
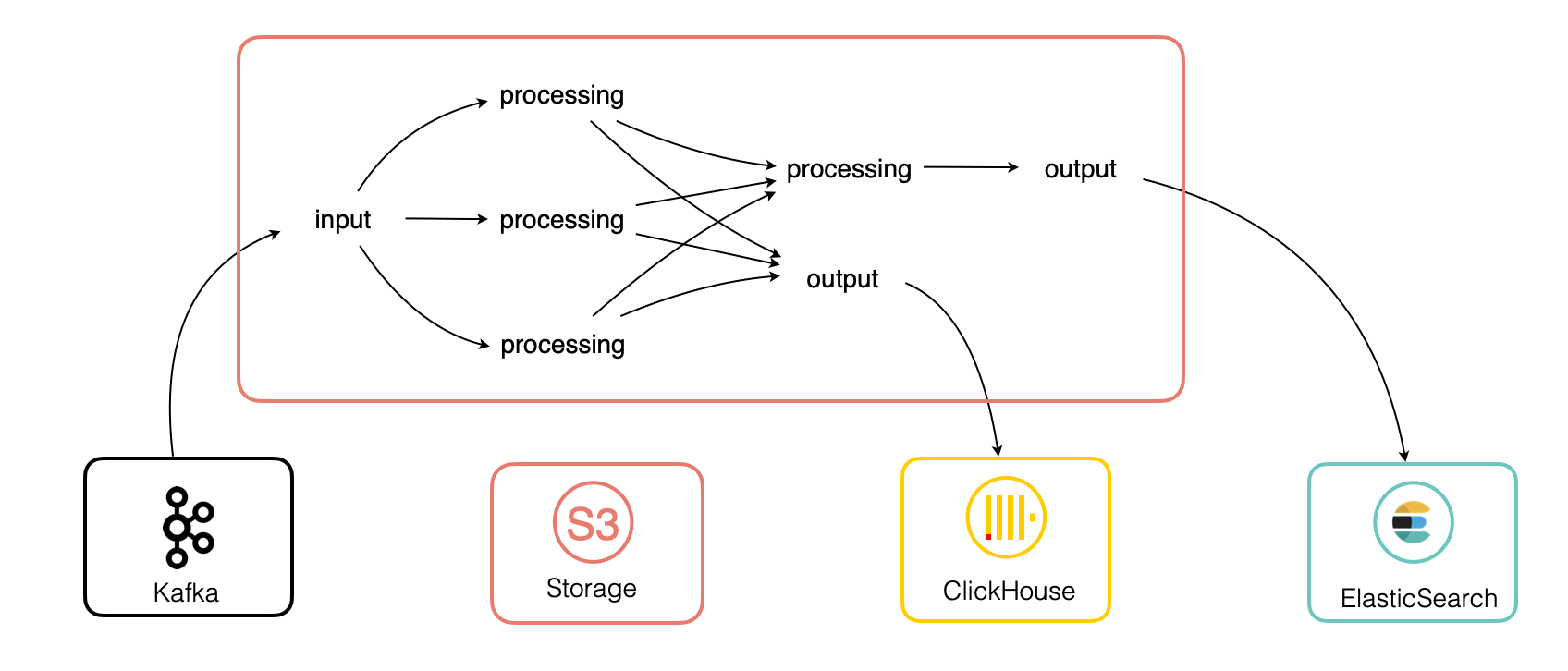
The Punch "punchline" object allows to easily connect to a variety of sources, parse and enrich the data in real-time and write to a variety of outputs.
CRD Format
All punchline are written following a Kubernetes Custom Resource Definition (CRD) format.
Punchlines respect the Kubernetes CRD format, but it is not a Kubernetes resource. You could see it as a config file where we specified all the steps and process of our data pipeline
Here is an example of a punchline:
apiVersion: punchline.punchplatform.io/v2
kind: StreamPunchline
metadata:
name: sample
labels:
vendor: thales
tenant: thales
spec:
dependencies:
- punch-parsers:com.mycompany:test-parsers:1.0.0
containers:
applicationContainer:
image: ghcr.io/punchplatform/punchline-java:8.0.0
env:
- name: JDK_JAVA_OPTIONS
value: "-Xms100m -Xmx450m"
dag:
- id: input
kind: source
type: kafka
out:
- id: processing
- id: processing
kind: function
type: flatmap
out:
- id: output
- id: output
kind: sink
type: elasticsearch
The most important fields are:
- kind: StreamPunchline that means a streaming punchline application.
- dag, stands for "Directed acyclic graph". It fully defines the execution graph, i.e. the chain of functions.
Each step within the dag is define with a "node".
There a 3 king of nodes:
- "Source": The data source used by the punchline;
- "Function": The intelligence to parse, filter and enrich the data;
- "Sink": The data destination used by the punchline;
In this example, there are three nodes. A source node reading from a Kafka source, a function node to process the data and an elasticsearch output node.
More info on their official website: https://punch-1.gitbook.io/punch-doc/basics/punchlines
Let's see more details about the node types.
Source nodes
The source nodes available for the punchline are:
- "Generator": Generate predefined messages, useful for debugging;
- "Elasticsearch": Read data from an Elasticsearch/Opensearch index;
- "Kafka": Read data from a Kafka topic;
- "File": Read data from file;
- "Lumberjack", "Syslog", "UDP", "Relp": Retrieve log from source.
Azure Event Hubs comes with a native integration of Kafka. It is the best way to retrieve data directly from Azure.
Function nodes
The function nodes available for the punchline are:
- "Filter": Filter the data according to a pattern;
- "Punchlet": Use Punch custom language to parse the data.
Punchlets are where Punchplatform capabilities really shines. It uses a custom language to parse data with speed, reliability, and a lot of advanced features.
There are more information in the official punchplatform website: https://punch-1.gitbook.io/punch-doc/nodes/functions/punchlet
In the Punchplatform tutorial, there are examples of punchlets used to parse logs from Azure.
Sink nodes
The sink nodes available for the punchline are:
- "Show": print data to Stdout;
- "Elasticsearch": Send data to an Elasticsearch/Opensearch index;
- "Kafka": Send data to a Kafka topic.
DBAAS offer a service of managed Opensearch/Elasticsearch on a K8saas cluster.
How to use Punch with k8saas ?
To use punchplatform in the K8saas ecosystem, there are three steps:
- mount your punchlets in a configmap
- mount your punchline in a configmap
- deploy the punch application
Example of a punchlets configmap:
apiVersion: v1
kind: ConfigMap
metadata:
name: k8saas-punch-audit-punchlets-cm
data:
print_root.punch: |
{
print(root);
}
Example of a punchline configmap:
apiVersion: v1
kind: ConfigMap
metadata:
name: k8saas-punch-audit-punchline-cm
data:
punchline.yml: |
apiVersion: punchline.punchplatform.io/v2
kind: StreamPunchline
metadata:
name: k8saas-punchline-sa-java
labels:
app: k8saas-punchline-sa-java
annotations:
# Enable Prometheus scraping
prometheus.io/scrape: 'true'
# Expose your metric on this port (can be any unused port)
prometheus.io/port: '7770'
spec:
containers:
applicationContainer:
image: ghcr.io/punchplatform/punchline-java:8.0.0
imagePullPolicy: IfNotPresent
env:
- name: JDK_JAVA_OPTIONS
value: "-Xms100m -Xmx450m"
dag:
- id: input
kind: source
type: kafka
out:
- id: punchlet_print_root
- id: punchlet_print_root
kind: function
type: punchlet_function
settings:
punchlets:
- /resources/print_root.punch
out:
- id: output
- id: output
kind: sink
type: elasticsearch
And here is the deployment for the application that will run the app:
apiVersion: apps/v1
kind: Deployment
metadata:
name: k8saas-punch-audit-dpl
labels:
app: k8saas-punch-audit-pod
annotations:
fluentbit.io/exclude: "true"
spec:
replicas: 1
selector:
matchLabels:
app: k8saas-punch-audit-pod
template:
metadata:
labels:
app: k8saas-punch-audit-pod
annotations:
fluentbit.io/exclude: "true"
spec:
containers:
- name: punchline
image: ghcr.io/punchplatform/punchline-java:8.0.0
imagePullPolicy: Always
args: ["/punchline.yml"]
ports:
- name: metrics
containerPort: 7770
volumeMounts:
- name: punchline
mountPath: /punchline.yml
subPath: punchline.yml
- name: punchlets
mountPath: /resources
volumes:
- name: punchline
configMap:
name: k8saas-punch-audit-punchline-cm
- name: punchlets
configMap:
name: k8saas-punch-audit-punchlets-cm
Then, you'll just have to deploy these three resources to your kubernetes cluster and the application will automatically start running and processing data according to the punchline.
In the section "Run the punchline in Kubernetes" of the Punchplatform tutorial, there is section dedicated to the deployment of a punchline in Kubernetes.
Monitoring
Two Grafana dashboards are available to monitor respectively:
- Insights about the app: the CPU consumption of every punchline node individually & the traversal time
- The acknowledgments and fail rate per punchline nodes over time.
Details on these dashboards, screenshots, and how to deploy them are available in the "Monitoring" section of the Punch test case.
Next Steps
Punchplatform tutorial
To really understand the power of the Punchplatform, you should have a look of this step-by-step real life example where we collect kubernetes logs from azure, parse them in real-time and index them in Opensearch: Punch tutorial.